Простая линейная регрессионная модель. Основы линейной регрессии. Пример: простой регрессионный анализ
Что такое регрессия?
Рассмотрим две непрерывные переменные x=(x 1 , x 2 , .., x n), y=(y 1 , y 2 , ..., y n).
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение
, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x , причём изменения в y вызываются именно изменениями в x , мы можем определить линию регрессии (регрессия y на x ), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова "регрессия" исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей "регрессировал" и "двигался вспять" к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x
называется независимой переменной или предиктором.
Y - зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x , т.е. это «предсказанное значение y »
- a - свободный член (пересечение) линии оценки; это значение Y , когда x=0 (Рис.1).
- b - угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b .
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия .
Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a
и b
- выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a
и b
является метод наименьших квадратов
(МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y
- предсказанный y
, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины остаток равен разнице и соответствующего предсказанного Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
"Влиятельное" наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть "влиятельным" наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для "влиятельных" наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению , которая подчиняется распределению с степенями свободы, где стандартная ошибка коэффициента

 ,
,
 - оценка дисперсии остатков.
- оценка дисперсии остатков.
Обычно если достигнутый уровень значимости нулевая гипотеза отклоняется.
![]()
где процентная точка распределения со степенями свободы что дает вероятность двустороннего критерия
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем, мы можем аппроксимировать значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется
, и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации , обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Y = b0 + b1 P
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b0 + b1 P2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 (Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 (Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на.40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p<.05 . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на.65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся "внутри диапазона."

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию (-.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p<.001 .
Итог
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
- Задача
- Расчет параметров модели
- Список литературы
Задача
По десяти кредитным учреждениям получены данные, характеризующие зависимость объема прибыли (Y) от среднегодовой ставки по кредитам (X 1), ставки по депозитам (X 2) и размера внутрибанковских расходов (X 3).
Требуется:
1. Осуществить выбор факторных признаков для построения двухфакторной регрессионной модели.
2. Рассчитать параметры модели.
3. Для характеристики модели определить:
Ш линейный коэффициент множественной корреляции,
Ш коэффициент детерминации,
Ш средние коэффициенты эластичности, бетта-, дельта- коэффициенты.
Дать их интерпретацию.
4. Осуществить оценку надежности уравнения регрессии.
5. Оценить с помощью t-критерия Стьюдента статистическую значимость коэффициентов уравнения множественной регрессии.
6. Построить точечный и интервальный прогнозы результирующего показателя.
7. Отразить результаты расчетов на графике.
1. Выбор факторных признаков для построения двухфакторной регрессионной модели
Линейная модель множественной регрессии имеет вид:
Y i = 0 + 1 x i 1 + 2 x i 2 + … + m x im + i
регрессионная модель детерминация корреляция
Коэффициент регрессии j показывает, на какую величину в среднем изменится результативный признак Y, если переменную x j увеличить на единицу измерения.
Статистические данные для 10 исследуемых кредитных учреждений по всем переменным даны в таблице 2.1 В этом примере n = 10, m = 3.
Таблица 2.1
Х 2 - ставка по депозитам;
Х 3 - размер внутрибанковских расходов.
Чтобы убедиться в том, что выбор объясняющих переменных оправдан, оценим связь между признаками количественно. Для этого вычислим матрицу корреляций (расчет проведен в Excel Сервис - Анализ данных - Корреляция). Результаты вычислений представлены в таблице 2.2.
Таблица 2.2
Проанализировав данные можно сделать вывод что на объем прибыли Y имеют влияние такие фактории как: среднегодовая ставка по кредитам Х 1 , ставка по депозитам Х 2 и размер внутрибанковских расходов Х3. Самую тесную корреляционную связь с переменной имеет Х 1 - среднегодовая ставка по кредитам (r yx 1 =0,925). В качестве второй переменной для построения модели выбираем меньшую величину коэффициента корреляции для избежания мультиколлинеарности. Мультиколлинеарность - это линейная, или близкая к ней связь между факторами. Таким образом при сравнении Х 2 и Х 3 ми выбираем Х 2 - ставка по депозитам так как она составляэт 0,705 что на 0,088 меньше чем Х 3 - размер внутрибанковских расходов которое составило 0,793.
Расчет параметров модели
Строим эконометрическую модель:
Y= f (Х 1 , Х 2 )
где Y - объем прибыли (зависимая переменная)
Х 1 - среднегодовая ставка по кредитам;
Х 2 - ставка по депозитам;
Оценка параметров регрессии осуществляется по методу наименьших квадратов, используя данные, приведенные в таблице 2.3
Таблица 2.3
Анализ уравнения множественной регрессии и методика определения параметров становятся более наглядными, если воспользоваться матричной формой записи уравнения
где Y - вектор зависимой переменной размерности 101, представляющий собой значение наблюдений Y i ;
Х - матрица наблюдений независимых переменных Х 1 и Х 2 , размерность матрицы равна 103;
Подлежащий оцениванию вектор неизвестных параметров размерности 31;
Вектор случайных отклонений размерности 101.
Формула для вычисления параметров регрессионного уравнения:
А= (Х Т Х) - 1 Х Т Y
Для операций с матрицами использовались следующие функции Excel:
ТРАНСП (массив ) для транспонирования матрицы Х. Транспонированной называется матрица Х Т, в которой столбцы исходной матрицы Х заменяются строками с соответствующими номерами;
МОБР (массив ) для нахождения обратной матрицы;
МУМНОЖ (массив1, массив 2), которая вычисляет произведение матриц. Здесь массив 1 и массив 2 перемножаемые массивы. При этом количество столбцов аргумента массив 1 должно быть таким же, как количество строк аргумента массив 2. Результатом является массив с таким же числом строк, как массив 1 и таким же числом столбцов, как массив 2.
Результаты вычислений, проведенные в Excel:
Уравнение зависимости объема прибыли от среднегодовой ставки по кредитам и ставки по депозитам можно записать в следующем виде:
у = 33,295 + 0,767х 1 + 0,017х 2
Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки, имеет вид:
Y=Х+е = Y+е
где Y - оценка значений Y, равная Х;
е - остатки регрессии.
Расчетные значения Y определяются путем последовательной подстановки в эту модель значений факторов, взятых для каждого наблюдения.
Прибыль зависит от среднегодовой ставки по кредитам и ставки по депозитам. То есть с увеличением ставки по депозитам на 1000 рублей приводит к увеличению прибыли на 1,7 рублей, при неизменной величине ставки по депозитам, а увеличение ставки депозитов в 2 раза приведет к увеличению прибыли в 1,534 раза при прочих неизменных условиях.
Характеристики регрессионной модели
Промежуточные вычисления представлены в таблице 2.4.
Таблица 2.4
|
(y i -) 2 |
(y i -) 2 |
е t |
(е t -е t-1 ) 2 |
(x i 1 -) 2 |
(x i 2 -) 2 |
||||||
Результаты регрессионного анализа содержатся в таблицах 2.5 - 2.7.
Таблица 2.5.
|
Наименование |
Результат |
|||
|
Коэффициент множественной корреляции |
||||
|
Коэффициент детерминации R 2 |
||||
|
Скорректированный R 2 |
||||
|
Стандартная ошибка |
||||
|
Наблюдения |
Таблица 2.6
Таблица 2.7
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
||
В третьем столбце содержатся стандартные ошибки коэффициентов регрессии, а в четвертом t-статистика, используемая для проверки значимости коэффициентов уравнения регрессии.
а) Оценка линейного коэффициента множественной корреляции
б) Коэффициент детерминации R 2
Коэффициент детерминации показывает долю вариации результативного признака под воздействием изучаемых факторов. Следовательно, 85,5% вариации зависимой переменной учтено в модели и обусловлено влиянием включенных факторов.
Скорректированный R 2
в) Средние коэффициенты эластичности, бета-, дельта - коэффициенты
Учитывая, что коэффициент регрессии невозможно использовать для непосредственной оценки влияния факторов на зависимую переменную из-за различия единиц измерения, используем коэффициент эластичности (Э) и бета-коэффициент , которые рассчитываются по формулам:
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора на 1 процент.
При увеличении среднегодовой ставки по кредитам на 1%, объем прибыли увеличится в среднем на 0,474%. При увеличении ставки по депозитам на 1%, объем прибыли увеличится в среднем на 0,041%.
где - среднестатистическое отклонение фактора j.
значение (x i 1 -) 2 =2742,4 табл. 2.4 столбец 10;
значение (x i 2 -) 2 =1113,6 табл. 2.4 столбец 11;
Бета-коэффициент, с математической точки зрения, показывает, на какую часть величины среднего квадратического отклонения меняется среднее значение зависимой переменной с изменением независимой переменной на одно среднеквадратическое отклонение при фиксированном на постоянном уровне значении остальных независимых переменных.
Это означает, что при увеличении среднегодовой ставки по кредитам на 17,456 тыс. руб. объем прибыли увеличится на 93,14 тыс. руб.; при увеличении среднегодовой ставки по кредитам и ставки по депозитам на 11,124 тыс. руб. объем прибыли увеличится на 1,3 тыс. руб.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта-коэффициентов j:
где - коэффициент парной корреляции между фактором j и зависимой переменной.
Влияние факторов на изменение объема прибыли повлияло так, что за счет изменения среднегодовой ставки по кредитам на 92,5% объем прибыли увеличится на 1,011 тыс. руб., за счет снижения ставки депозитов на 64,5% объем прибыли снизится на 0,01 тыс. руб.
4. Оценка надежности уравнения регрессии
Проверку значимости уравнения регрессии произведем на основе вычисления F-критерия Фишера:
По таблице определим критическое значение при =0,05 F ; m ; n - m -1 = F 0,05 ; 2 ; 7 =4,74. Т.к. F расч = 20,36 > F крит =4,74, то уравнение регрессии с вероятностью 95% можно считать статистически значимым. Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель. Согласно общим предположениям регрессионного анализа остатки должны вести себя как независимые одинаково распределенные случайные величины. Проверку независимости остатков проведем с помощью критерия Дарбина-Уотсона (данные в табл. 2.4 столбцы 7,9)
DW близко к 2, значит, автокорреляция отсутствует. Для точного определения наличия автокорреляции используют критические значения d low и d high из таблицы, при =0,05, n =10, k =2:
d low =0,697 d high =1,641
Получаем, что d high < DW < 4-d high (1,641 < 2,350 < 2,359), можно сделать вывод об отсутствии автокорреляции. Это является одним из подтверждений высокого качества модели построенного по МНК.
5. Оценка с помощью t -критерия Стьюдента статистической значимости коэффициентов уравнения регрессии
Значимость коэффициентов уравнения регрессии а 0 , а 1 , а 2 оценим с использованием t -критерия Стьюдента.
b 11 =58,41913
b 22 =0,00072
b 33 =0,00178
Стандартная ошибка =6,19 (табл.2.5 строка 4)
Расчетные значения t -критерия Стьюдента приведены в табл.2.7 столбец 4.
Табличное значение t -критерия при 5% уровне значимости и степенях свободы
n - m - 1 = 10 - 2 - 1 = 7 =2,365
Если расчетное значение по модулю больше критического, то делается вывод о статистической значимости коэффициента регрессии, в противном случае коэффициенты регрессии статистически не значимы.
Так как <t кр, то коэффициенты регрессии а 0 , а 2 незначимы.
Так как >t кр, то коэффициент регрессии а 1 значим.
6. Построение точечного и интервального прогноза результирующего показателя
Прогнозные значения X 1,11 и X 2,11 можно определить с помощью методов экспертных оценок, с помощью средних абсолютных приростов или вычислить на основе экстраполяционных методов.
В качестве прогнозных оценок для Х 1 и Х 2 возьмем среднее значение каждой переменной увеличенное на 5% х 1 =42,41,05=44,52; х 2 =160,81,05=168,84.
Подставим в нее значения прогнозных факторов Х 1 и Х 2 .
у (х р ) = 33,295+0,76744,52+0,017168,84=70,365
Доверительный интервал прогноза будет иметь следующие границы.
Верхняя граница прогноза: у (х р ) + u
Нижняя граница прогноза: у (х р ) - u
u =S e t кр, S e = 6,19 (табл.2.5 строка 4)
t кр = 2,365 (при =0,05)
= (1; 44,52; 168,84)
u =6, 192,365=7,258
Результат прогноза представлен в таблице 2.8.
Таблица 2.8
|
Нижняя граница |
Верхняя граница |
||
|
70,365 - 7,258=63,107 |
70,365 + 7,258=77,623 |
7. Результаты расчетов отражены на графике:
Построена модель множественной регрессии зависимости объема прибыли У от ставки по депозитам Х 1 и внутрибанковским расходам Х 2:
у = 33,295 + 0,767х 1 + 0,017х 2
Коэффициент детерминации R 2 =0,855 свидетельствует о сильной зависимости факторов. В модели отсутствует автокорреляция остатков. Т.к. F расч =20,36 > F крит =7,74, то уравнение регрессии с вероятностью 95% можно считать статистически значимым.
Величина прибыли при неизменных условиях с вероятностью 95% будет находиться в интервале от 63,107 до 77,623.
Эти факторы тесно связаны между собой, что свидетельствует о наличии мультиколлинеарности. Параметры множественной регрессии теряют экономический смысл, оценки параметров ненадежны. Модель непригодна для анализа и прогнозирования. Включение факторов в модель статистически не оправдано. Причиной неадекватности модели послужили ошибки в организации, даны недостоверные или не учтены факторы в модели, погрешности в задании исходных данных.
Анализ показал, что зависимая переменная, то есть объем прибыли, имеет тесную связь с индексом ставки по кредитам и индексом размера внутрибанковских расходов. В результате чего кредитным учреждениям следует уделить особое внимание на эти показатели, искать пути уменьшения и оптимизации внутрибанковских расходов и вести эффективные ставки по кредитам.
Сокращение расходов банка возможно за счет экономии административно-хозяйственных расходов и уменьшения стоимости привлекаемых пассивов.
Экономия расходов может предусматривать сокращение персонала или уменьшение заработной платы, закрытие убыточных дополнительных офисов и филиалов.
Список литературы
1. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов. - М.: ЮНИТИ - ДАНА, 2003.
2. Магнус Я.Р., Катышев П.К., Персецкий А.А. Эконометрика. Начальный курс. - М.: Дело, 2001.
3. Бородич С.А. эконометрика: Учеб. Пособие. - Мн.: Новое знание, 2006.
4. Елисеева И.И. Эконометрика: Учебник. - М., 2010.
Размещено на Allbest.ru
...Подобные документы
Выбор факторных признаков для построения регрессионной модели неоднородных экономических процессов. Построение диаграммы рассеяния. Анализ матрицы коэффициентов парной корреляции. Определение коэффициентов детерминации и средних ошибок аппроксимации.
контрольная работа , добавлен 21.03.2015
Выбор факторных признаков для двухфакторной модели с помощью корреляционного анализа. Расчет коэффициентов регрессии, корреляции и эластичности. Построение модели линейной регрессии производительности труда от факторов фондо- и энерговооруженности.
задача , добавлен 20.03.2010
Проектирование регрессионной модели по панельным данным. Скрытые переменные и индивидуальные эффекты. Расчет коэффициентов однонаправленной модели с фиксированными эффектами по панельным данным в MS Excel. Выбор переменных для построения данной регрессии.
курсовая работа , добавлен 26.08.2013
Группировка предприятий по среднегодовой стоимости производственных фондов. Сглаживание скользящей средней и ее центрирование. Определение коэффициента линейной регрессионной модели и показателей детерминации. Коэффициенты эластичности и их интерпретация.
контрольная работа , добавлен 06.05.2015
Расчет параметров линейного уравнения множественной регрессии; определение сравнительной оценки влияния факторов на результативный показатель с помощью коэффициентов эластичности и прогнозного значения результата; построение регрессионной модели.
контрольная работа , добавлен 29.03.2011
Построение и анализ классической многофакторной линейной эконометрической модели. Вид линейной двухфакторной модели, её оценка в матричной форме и проверка адекватности по критерию Фишера. Расчет коэффициентов множественной детерминации и корреляции.
контрольная работа , добавлен 01.06.2010
Построение линейной модели зависимости цены товара в торговых точках. Расчет матрицы парных коэффициентов корреляции, оценка статистической значимости коэффициентов корреляции, параметров регрессионной модели, доверительного интервала для наблюдений.
лабораторная работа , добавлен 17.10.2009
Определение методом регрессионного и корреляционного анализа линейных и нелинейных связей между показателями макроэкономического развития. Расчет среднего арифметического по столбцам таблицы. Определение коэффициента корреляции и уравнения регрессии.
контрольная работа , добавлен 14.06.2014
Проведение анализа экономической деятельности предприятий отрасли: расчет параметров линейного уравнения множественной регрессии с полным перечнем факторов, оценка статистической значимости параметров регрессионной модели, расчет прогнозных значений.
лабораторная работа , добавлен 01.07.2010
Порядок построения линейного регрессионного уравнения, вычисление его основных параметров и дисперсии переменных, средней ошибки аппроксимации и стандартной ошибки остаточной компоненты. Построение линии показательной зависимости на поле корреляции.
После того как с помощью корреляционного анализа выявлено наличие статистически значимых связей между переменными и оценена степень их тесноты, обычно переходят к математическому описанию конкретного вида зависимостей с помощью регрессионного анализа.
Корреляционная зависимость между двумя переменными – это функциональная зависимость между одной переменной и ожидаемым (условным средним) значением другой. Уравнение такой зависимости между двумя переменными называется уравнением регрессии. В случае, если переменных две (одна зависимая и одна независимая), то регрессия называется простой, а если их более двух, то множественная. Если зависимость между переменными линейная, то регрессия называется линейной, в противном случае – нелинейной.
Рассмотрим подробно простую линейную регрессию. Модель такой зависимости может быть представлена в виде
y = α + βx + ε, (1.1)
где у – зависимая переменная (результативный признак);
х – независимая переменная (факторный признак);
α – свободный член уравнения регрессии или константа;
β – коэффициент уравнения регрессии;
ε – случайная величина, характеризующая отклонения фактических значений зависимой переменной у от модельных или теоретических значений, рассчитанных по уравнению регрессии.
При этом предполагается, что объясняющая переменная х – величина не случайная, а объясняемая y – случайная. В дальнейшем это предположение можно будет убрать.
1.2.1. Метод наименьших квадратов (мнк) и его предпосылки
α и β – это параметры модели регрессии (1.1), которые должны быть оценены на основе выборочных данных. На основе этих же выборочных данных должна быть оценена дисперсия ε. Одним из методов вычисления таких оценок является классический метод наименьших квадратов (МНК). Суть МНК состоит в минимизации суммы квадратов отклонений фактических значений зависимой переменной у от их условных математических ожиданий , определяемых по уравнению регрессии:=α + βx , в предположении, что математическое ожидание ε равно нулю. Математическое ожидание y обозначим через, а сумму квадратов отклонений черезQ(.
Здесь суммирование ведётся по всей генеральной совокупности. Данную сумму называют остаточной суммой квадратов.
Чтобы
минимизировать эту функцию по параметрам
обратимся к условиям первого порядка,
полученным дифференцированиемQ()
по![]()
Далее пусть для оценки параметров модели (1.1) организована выборка, содержащая n пар значений переменных (x i ,y i), где i принимает значения от 1 до n (i =). Приравнивая частные производные к нулю и переходя от генеральной совокупности к выборке (заменив параметры на их оценки), получим систему нормальных уравнений для вычисления оценок параметровα и β. Обозначим эти оценки соответственно как а и b . Получим следующую систему нормальных уравнений
Если оценённое уравнение обозначить как y = a + bx + e , где е – одна из реализаций случайной величины ε, соответствующая конкретной выборки, то выражение в скобках системы нормальных уравнений есть не что иное, как остаток уравнения регрессии е i = y i и тогда первое уравнение этой системы примет вид = 0. То есть среднее значение остатков равно нулю. Таким образом, если уравнение регрессии содержит константу, то сумма остатков в оценённом уравнении всегда равна нулю.
Второе уравнение системы в этих обозначениях даёт = 0, т. е. векторы значений независимой переменной и остатков ортогональны (независимы).
Приведём один из вариантов формул для вычисления таких оценок:
a = – b, b = . (1.2)
Известно также, что несмещённой оценкой дисперсии случайных отклонений является остаточная дисперсия, вычисляемая из соотношения:
= .
Итак, оценённая модель линейной парной регрессии имеет вид
y = a + bx + e , (1.3)
где е – наблюдаемые отклонения фактических значений зависимой переменной у от расчётных , которые рассчитываются из соотношения=a + bx .
Различие между ε и е состоит в том, что ε – это случайная величина и предсказать её значения не представляется возможным, в то время как е – это наблюдаемые значения отклонений (е = у –) и эти отклонения можно считать случайной выборкой из совокупности значений остатков регрессии и их можно анализировать с использованием статистических методов.
Как было отмечено, МНК строит оценки регрессии на основе минимизации суммы квадратов отклонений или остатков ε, поэтому важно знать их свойства. Для получения «хороших» МНК-оценок необходимо, чтобы выполнялись следующие основные предпосылки относительно остатков модели (1.1), называемые предположениями Гаусса – Маркова.
Первое предположение говорит о том, что математическое ожидание регрессионных остатков равно нулю и подразумевает, что в среднем, линия регрессии должна быть истинной. Предположение 3 утверждает, что все регрессионные остатки имеют одну и ту же дисперсию, и называется предположением гомоскедастичности, а предположение 4 исключает любую форму автокорреляции между ними, т. е. подразумевает нулевую корреляцию между различными регрессионными остатками. Вместе взятые эти предположения означают, что регрессионные остатки являются некоррелированными извлечениями из генеральной совокупности с распределением, имеющем нулевое математическое ожидание и постоянную дисперсию .
Предположение 2 утверждает независимость векторов значений независимой переменной и регрессионных остатков.
Известно, что если выполняются эти четыре предположения, то верна теорема Гаусса – Маркова , утверждающая, что в этом случае МНК-оценка b является наилучшей линейной несмещённой оценкой параметра β. Наилучшей в смысле эффективности.
Кроме сформулированных предположений вводится ещё одно, которое позволило бы сформулировать показатели точности уравнения регрессии и его оценок. Эта предпосылка утверждает, что остатки должны следовать нормальному закону распределения с нулевым математическим ожиданием и постоянной дисперсией.
В дальнейшем уравнение =a + b x будем называть выборочным уравнением регрессии или просто уравнением регрессии, а его коэффициенты, соответственно, свободным членом (а ) и коэффициентом уравнения регрессии (b ).
Свободный член уравнения регрессии обычно не интерпретируется. Коэффициент регрессии показывает, насколько в среднем изменится зависимая переменная (в своих единицах измерения) при изменении независимой переменной на единицу своего измерения.
При этом, необходимо иметь в виду, что рассматриваемые коэффициенты являются оценками параметров уравнения регрессии =α + βx со всеми вытекающими отсюда последствиями, в том числе и необходимостью получения оценок точности уравнения регрессии и его параметров.
Рассмотрим некоторые из них.
16.1 Простая линейная регрессия
Чтобы вызвать регрессионный анализ в SPSS, выберите в меню Analyze... (Анализ) Regression... (Регрессия). Откроется соответствующее подменю.

Рис. 16.1:
При изучении линейного регрессионного анализа снова будут проведено различие между простым анализом (одна независимая переменная) и множественным анализом (несколько независимых переменных). Никаких принципиальных отличий между этими видами регрессии нет, однако простая линейная регрессия является простейшей и применяется чаще всех остальных видов.
Этот вид регрессии лучше всего подходит для того, чтобы продемонстрировать основополагающие принципы регрессионного анализа. Рассмотрим пример из раздела корреляционный анализ с зависимостью показателя холестерина спустя один месяц после начала лечения от исходного показателя. Можно легко заметить очевидную связь: обе переменные развиваются в одном направлении и множество точек, соответствующих наблюдаемым значениям показателей, явно концентрируется (за некоторыми исключениями) вблизи прямой (прямой регрессии). В таком случае говорят о линейной связи.
у = b х + а
,
где b - регрессионные коэффициенты, a - смещение по оси ординат (OY).
Смещение по оси ординат соответствует точке на оси Y (вертикальной оси), где прямая регрессии пересекает эту ось. Коэффициент регрессии b через соотношение:
b = tg(a)
- указывает на угол наклона прямой.
При проведении простой линейной регрессии основной задачей является определение параметров b и а. Оптимальным решением этой задачи является такая прямая, для которой сумма квадратов вертикальных расстояний до отдельных точек данных является минимальной.
Если мы рассмотрим показатель холестерина через один месяц (переменная chol1
) как зависимую переменную (у), а исходную величину как независимую переменную (х),
то тогда для проведения регрессионного анализа нужно будет определить параметры соотношения:
chol1 = b chol0 + a
После определения этих параметров, зная исходный показатель холестерина, можно спрогнозировать показатель, который будет через один месяц.
Расчёт уравнения регрессии
Выберите в меню Analyze... (Анализ) Regression...(Регрессия) Linear... (Линейная). Появится диалоговое окно Linear Regression (Линейная регрессия).
Перенесите переменную chol1 в поле для зависимых переменных и присвойте переменной chol0 статус независимой переменной.
Ничего больше не меняя, начните расчёт нажатием ОК.

Рис.16.2
Вывод основных результатов выглядит следующим образом:
Model Summary (Сводная таблица по модели)
| Model (Модель) | R | R Square (R-квадрат) | Adjusted R Square (Скорректир. R-квадрат) | Std. Error of the Estimate (Стандартная ошибка оценки) |
| 1 | ,861 а | ,741 | ,740 | 25,26 |
а. Predictors: (Constant), Cholesterin, Ausgangswert (Влияющие переменные: (константы), холестерин, исходная величина)
| Model (Модель) | Sum of Squares (Сумма Квадратов) | df | Mean Square (Среднее значение квадрата) | F | Sig. (Значимость) | |
| 1 | Regression (Регрессия) | 314337,948 | 1 | 314337,9 | 492,722 | ,000 a |
| Residual (Остатки) | 109729,408 | 172 | 637,962 | |||
| Total (Сумма) | 424067,356 | 173 |
a. Predictors: (Constant), Cholesterin, Ausgangswert (Влияющие переменные: (константа), холестерин, исходная величина).
b. Dependent Variable: Cholesterin, nach 1 Monat (Зависимая переменная холестерин через 1 месяц)
Coefficients (Коэффициенты) а
| Model (Модель) | Unstandardized Coefficients |
t | Sig. (Значимость) | |||
| B | Std: Error (Станд. ошибка) |
ß (Beta) | ||||
| 1 | (Constant) (Константа) | 34,546 | 9,416 | 3,669 | ,000 | |
| Cholesterin, Ausgangswert | ,863 | ,039 | ,861 | 22,197 | ,000 | |
a. Dependent Variable (Зависимая переменная)
Рассмотрим сначала нижнюю часть результатов расчётов. Здесь выводятся коэффициент регрессии b и смещение по оси ординат а под именем "константа". То есть, уравнение регрессии выглядит следующим образом:
chol1 = 0,863 chol0 + 34,546
Если значение исходного показателя холестерина составляет, к примеру, 280, то через один месяц можно ожидать показатель равный 276.
Частные рассчитанных коэффициентов и их стандартная ошибка дают контрольную величину Т; соответственный уровень значимости относится к существованию ненулевых коэффициентов регрессии. Значение коэффициента ß будет рассмотрено при изучении многомерного анализа .
Средняя часть расчётов отражает два источника дисперсии: дисперсию, которая описывается уравнением регрессии (сумма квадратов, обусловленная регрессией) и дисперсию, которая не учитывается при записи уравнения (остаточная сумма квадратов). Частное от суммы квадратов, обусловленных регрессией и остаточной суммы квадратов называется "коэфициентом детерминации". В таблице результатов это частное выводится под именем "R-квадрат". В нашем примере мера определённости равна:
314337,948 / 424067,356 = 0,741
Эта величина характеризует качество регрессионной прямой, то есть степень соответствия между регрессионной моделью и исходными данными. Мера определённости всегда лежит в диапазоне от 0 до 1. Существование ненулевых коэффициентов регрессии проверяется посредством вычисления контрольной величины F, к которой относится соответствующий уровень значимости.
В простом линейном регрессионном анализе квадратный корень из коэфициента детерминации, обозначаемый "R", равен корреляционному коэффициенту Пирсона. При множественном анализе эта величина менее наглядна, нежели сам коэфициент детерминации. Величина "Cмещенный R-квадрат" всегда меньше, чем несмещенный. При наличии большого количества независимых переменных, мера определённости корректируется в сторону уменьшения. Принципиальный вопрос о том, может ли вообще имеющаяся связь между переменными рассматриваться как линейная, проще и нагляднее всего решать, глядя на соответствующую диаграмму рассеяния. Кроме того, в пользу гипотезы о линейной связи говорит также высокий уровень дисперсии, описываемой уравнением регрессии.
И, наконец, стандартизированные прогнозируемые значения и стандартизированные остатки можно предоставить в виде графика. Вы получите этот график, если через кнопку Plots...(Графики) зайдёте в соответствующее диалоговое окно и зададите в нём параметры *ZRESID и *ZPRED в качестве переменных, отображаемых по осям у и х соответственно. В случае линейной регрессии остатки распределяются случайно по обе стороны от горизонтальной нулевой линии.
Сохранение новых переменных
Многочисленные вспомогательные значения, рассчитываемые в ходе построения уравнения регрессии, можно сохранить как переменные и использовать в дальнейших расчётах.
Для этого в диалоговом окне Linear Regression (Линейная регрессия) щёлкните на кнопке Save (Сохранить). Откроется диалоговое окно Linear Regression: Save (Линейная регрессия: Сохранение) как изображено на рисунке 16.3.

Рис. 16.3:
Интересными здесь представляются опции Standardized (Стандартизированные значения) и Unstandardized (Нестандартизированные значения), которые находятся под рубрикой Predicted values (Прогнозируемые величины опции). При выборе опции Не стандартизированные значения будут рассчитывается значения у, которое соответствуют уравнению регрессии. При выборе опции Стандартизированные значения прогнозируемая величина нормализуется. SPSS автоматически присваивает новое имя каждой новообразованной переменной, независимо от того, рассчитываете ли Вы прогнозируемые значения, расстояния, прогнозируемые интервалы, остатки или какие-либо другие важные статистические характеристики. Нестандартизированным значениям SPSS присваивает имена pre_1 (predicted value), pre_2 и т.д., а стандартизированным zpr_l.
Щёлкните в диалоговом окне Linear Regression: Save (Линейная регрессия: Сохранение) в поле Predicted values (Прогнозируемые значения) на опции Unstandardized (Нестандартизированные значения).
В редакторе данных будет образована новая переменная под именем рrе_1 и добавлена в конец списка переменных в файле. Для объяснения значений, находящихся в переменной рrе_1 , возьмём случай 5. Для случая 5 переменная рrе_1 содержит нестандартизированное прогнозируемое значение 263,11289. Это прогнозируемое значение слегка отличается в сторону увеличения от реального показателя содержания холестерина, взятого через один месяц (chol1 ) и равного 260. Нестандартизированное прогнозируемое значение для переменной chol1 , так же как и другие значения переменной рге_1, было вычислено исходя из соответствующего уравнения регрессии.
Если мы в уравнение регрессии:
chol1 = 0,863 chol0 + 34,546
подставим исходное значение для chol0 (265), то получим: chol1 = 0,863 265 + 34,546 = 263,241
Небольшое отклонение от значения, хранящегося в переменной рге_1 объясняется тем, что SPSS использует в расчётах более точные значения, чем те, которые выводятся в окне просмотра результатов.
Добавьте для этого в конец файла hyper.sav , ещё два случая, используя фиктивные значения для переменной chol0. Пусть к примеру, это будут значения 282 и 314.
Мы исходим из того, что нам не известны значения показателя холестерина через месяц после начала лечения, и мы хотим спрогнозировать значение переменной chol1 .
Оставьте предыдущие установки без изменений и проведите новый расчёт уравнения регрессии.
В конце списка переменных добавится переменная рге_2. Для нового добавленного случая (№175) для переменной chol1 будет предсказано значение 277,77567, а для случая №176 - значение 305,37620.
Построение регрессионной прямой
Чтобы на диаграмме рассеяния изобразить регрессионную прямую, поступите следующим образом:


Рис. 16.9:
Выбор осей
Для диаграмм рассеяния часто оказывается необходимой дополнительная корректировка осей. Продемонстрируем такую коррекцию при помощи одного примера. В файле raucher.sav находятся десять фиктивных наборов данных. Переменная konsum указывает на количество сигарет, которые выкуривает один человек в день, а переменная puls на количество времени, необходимое каждому испытуемому для восстановления пульса до нормальной частоты после двадцати приседаний. Как было показано ранее, постройте диаграмму рассеяния с внедрённой регрессионной прямой.
В диалоговом окне Simple Scatterplot (Простая диаграмма рассеяния) перенесите переменную puls в поле оси Y, а переменную konsum - в поле оси X. После соответствующей обработки данных в окне просмотра появится диаграмма рассеяния, изображённая на рисунке 16.10.
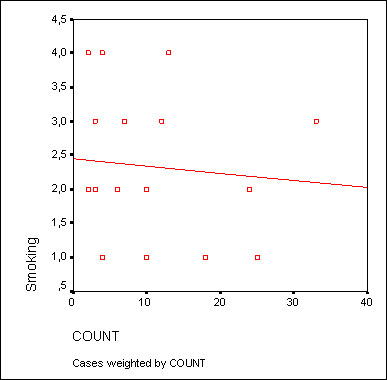
Рис. 16.10:
Так как никто не выкуривает минус 10 сигарет в день, точка начала отсчёта оси X является не совсем корректной. Поэтому эту ось необходимо откорректировать.

В окне просмотра Вы увидите откорректированную диаграмму рассеяния (см. рис. 16.13).

Рис. 16.13:
На откорректированной диаграмме рассеяния теперь стало проще распознать начальную точку на оси Y, которая образуется при пересечении с регрессионной прямой. Значение этой точки примерно равно 2,9. Сравним это значение с уравнением регрессии для переменных puls (зависимая переменная) и konsum (независимая переменная). В результате расчёта уравнения регрессии в окне отображения результатов появятся следующие значения:
Coefficients (Коэффициенты) а
| Model (Модель) | Unstandardized Coefficients (Не стандартизированные коэффициенты) |
Standardized Coefficients (Стандартизированные коэффициенты) | t | Sig. (Значимость) | ||
| B | Std: Error (Станд. ошибка) |
ß (Beta) | ||||
| 1 | (Constant) (Константа) | 2,871 | ,639 | 4,492 | ,002 | |
| tgl. Zigarettenkonsum | ,145 | ,038 | ,804 | 3,829 | ,005 | |
a. Dependent Variable: Pulsfrequenz unter 80 (Зависимая переменная: частота пульса ниже 80)
Что дает следующее уравнение регрессии:
puls = 0,145 konsum + 2,871
Константа в вышеприведенном уравнении регрессии (2,871) соответствует точке на оси Y, которая образуется в точке пересечения с регрессионной прямой.
ПОСТРОЕНИЕ УРАВНЕНИЙ РЕГРЕССИИ.
МОДУЛЬ MULTIPLE REGRESSION СИСТЕМЫ STATISTICA.
Цель занятия:
1. Изучить структуру и назначение статистического модуля Multiple Regression системы STATISTICA.
2. Освоить основные приемы работы в модуле Multiple Regression системы STATISTICA.
3. Освоить процедуру построения линейной регрессии в модуле Multiple Regression.
4. Самостоятельно решить задачу о нахождении коэффициентов линейной регрессионной модели.
Общие положения.
Статистический модуль Multiple Regression – Множественная регрессия включает в себя набор средств проведения регрессионного анализа данных.
Линейный регрессионный анализ.
В линейный регрессионный анализ входит широкий круг задач, связанных с построением зависимостей между группами числовых переменных X º (x 1 , ..., x p) и Y = (y 1 ,..., y m).
Предполагается, что Х - независимые переменные (факторы) влияют на значения Y - зависимых переменных (откликов). По имеющимся эмпирическим данным (X i , Y i ), i = 1, ..., n требуется построить функцию f (X ), которая приближенно описывала бы изменение Y при изменении X . Искомая функция записывается в следующем виде: f (X ) = f (X, q) + e, где q - неизвестный многомерный параметр, e - случайная составляющая с нулевым средним, f (X, q) является условным математическим ожиданием Y при условии известного X и называется регрессией Y по X.
Простая линейная регрессия.
Функция f (x, q) имеет вид f (x , q) = A + bx , где q = (A, b ) - неизвестные параметры. Относительно имеющихся наблюдений (x i , y i ), где i = 1,...,n , полагаем, что y i = A + bx i + e i . e 1 , ..., e n – ошибка вычисления Y по принятой модели. Для нахождения параметров широко используют метод наименьших квадратов .
Значения параметров модели находят из уравнения:
Min по (A, b )
Чтобы упростить формулы, положим x i = x i - ; получим:
y i = a + b (x i - ) + e i , i = 1, ..., n ,
где = , a = A + b .
Сумму  минимизируем по (a,b
), приравнивая нулю производные по a
и b
; получим систему линейных уравнений относительно a
и b
. Ее решение () легко находится:
минимизируем по (a,b
), приравнивая нулю производные по a
и b
; получим систему линейных уравнений относительно a
и b
. Ее решение () легко находится:
 .
.
Свойства оценок . Нетрудно показать, что если M e i = 0, D e i = s 2 , то
1) M = а, М = b , т.е. оценки несмещенные;
2) D = s 2 / n , D = s 2 / ;
3) cov () = 0;
если дополнительно предположить нормальность распределения e i , то
4) оценки и нормально распределены и независимы;
5) остаточная сумма квадратов
Q
2 = 
независима от ( , ), а Q 2 / s 2 распределена по закону хи-квадрат с n -2 степенями свободы.
Вызов статистического модуля Multiple Regression – Множественная регрессия выполним используя пиктограмму в левом нижнем углу (рис.1). В стартовом диалоговом окне этого модуля (рис. 2) при помощи кнопки Variables указываются зависимая (dependent) и независимые(ая) (independent) переменные.
В поле MD deletion указывается способ исключения из обработки недостающих данных:
casewise - игнорируется вся строка, в которой есть хотя бы одно пропущенное значение;
mean Substitution - взамен пропущенных данных подставляются средние значения переменных;
pairwise - попарное исключение данных с пропусками из тех переменных, корреляция которых вычисляется.
При необходимости выборочного включения данных для анализа следует воспользоваться кнопкой select cases.

Рисунок – 1 Вызов статмодуля Multiple Regression

Рисунок – 2 Диалоговое окно Multiple Regression
После выбора всех параметров анализа нажмите кнопку OK.
Стандартная линейная модель имеет вид:
Y = a 1 + a 2 X 1 + + a 3 X 2 + + a 3 X 3 + ……+ + a n X n
Нажатие на кнопку ОК приведет к появлению окна Multiple Regressions Results (результаты регрессионного анализа) (рис. 3), с помощью которого можно просмотреть результаты анализа в деталях.

Рисунок – 3 Окно Multiple Regressions Results (результаты регрессионного анализа)
Окно результатов имеет следующую структуру. Верхняя часть окна – информационная. Нижняя часть окна – содержит функциональные кнопки, позволяющие получить дополнительную информацию об анализе данных.
В верхней части окна приводятся наиболее важные параметры полученной регрессионной модели:
Dependent – имя зависимой переменной (Y);
Multiple R - коэффициент множественной корреляции;
Характеризует тесноту линейной связи между зависимой и всеми независимыми переменными. Может принимать значения от 0 до 1.
R 2 или RI - коэффициент детерминации;
Численно выражает долю вариации зависимой переменной, объясненную с помощью регрессионного уравнения. Чем больше R 2 , тем большую долю вариации объясняют переменные, включенные в модель.
No. Of Cases – число случаев, по которым построена регрессия;
adjusted R - скорректированный коэффициент множественной корреляции;
Этот коэффициент лишен недостатков коэффициента множественной корреляции. Включение новой переменной в регрессионное уравнение увеличивает RI не всегда, а только в том случае, когда частный F-критерий при проверке гипотезы о значимости включаемой переменной больше или равен 1. В противном случае включение новой переменной уменьшает значение RI и adjusted R 2 .
adjusted R 2 или adjusted RI - скорректированный коэффициент детерминации;
Скорректированный R 2 можно с большим успехом (по сравнению с R 2) применять для выбора наилучшего подмножества независимых переменных в регрессионном уравнении
F - F-критерий;
df - число степеней свободы для F-критерия;
p - вероятность нулевой гипотезы для F-критерия;
Standard error of estimate - стандартная ошибка оценки (уравнения);
Intercept - свободный член уравнения, параметр а 1 ;
Std.Error - стандартная ошибка свободного члена уравнения;
t - t-критерий для свободного члена уравнения;
p - вероятность нулевой гипотезы для свободного члена уравнения.
Beta - b-коэффициенты уравнения.
Это стандартизированные регрессионные коэффициенты, рассчитанные по стандартизированным значениям переменных. По их величине можно сравнить и оценить значимость зависимых переменных, так как b-коэффициент показывает на сколько единиц стандартного отклонения изменится зависимая переменная при изменении на одно стандартное отклонение независимой переменной при условии постоянства остальных независимых переменных. Свободный член в таком уравнении равен 0.
При помощи кнопок диалогового окна Multiple Regressions Results (рис. 3) результаты регрессионного анализа можно просмотреть более детально.
Кнопка Summary: Regression results - позволяет просмотреть основные результаты регрессионного анализа (рис. 4, 5): BETA - b-коэффициенты уравнения; St. Err. of BETA - стандартные ошибки b-коэффициентов; В - коэффициенты уравнения регрессии; St. Err. of B - стандартные ошибки коэффициентов уравнения регрессии; t (95) - t-критерии для коэффициентов уравнения регрессии; р-level - вероятность нулевой гипотезы для коэффициентов уравнения регрессии.


Рисунок - 4
Таким образом в результате проведенного регрессионного анализа получено следующее уравнение взаимосвязи между откликом (Y) и независимой переменной (Х):
Y = 17,52232 – 0,06859Х
Свободный коэффициент уравнения значим на 5% уровне (p-level < 0,05). Коэффициентом при Х следует пренебречь. Это уравнение объясняет только 0,028% (R 2 = 0,000283) вариации зависимой переменной.







