Как в экселе найти повторяющиеся ячейки. Лучшие программы для поиска дубликатов (одинаковых) файлов. Поиск и выделение цветом совпадающих строк в Excel
Разное (39)
Баги и глюки Excel (3)
Как получить список уникальных(не повторяющихся) значений?
Представим себе большой список различных наименований, ФИО, табельных номеров и т.п. А необходимо из этого списка оставить список все тех же наименований, но чтобы они не повторялись - т.е. удалить из этого списка все дублирующие записи. Как это иначе называют: создать список уникальных элементов, список неповторяющихся, без дубликатов. Для этого существует несколько способов: встроенными средствами Excel, встроенными формулами и, наконец, при помощи кода Visual Basic for Application(VBA) и сводных таблиц. В этой статье рассмотрим каждый из вариантов.
При помощи встроенных возможностей Excel 2007 и выше
В Excel 2007 и 2010 это сделать проще простого - есть специальная команда, которая так и называется - . Расположена она на вкладке Данные (Data)
подраздел Работа с данными (Data tools)
Как использовать данную команду. Выделяете столбец(или несколько) с теми данными, в которых надо удалить дублирующие записи. Идете на вкладку Данные (Data) -Удалить дубликаты (Remove Duplicates) .
Если выделить один столбец, но рядом с ним будут еще столбцы с данными(или хотя бы один столбец), то Excel предложит выбрать: расширить диапазон выборки этим столбцом или оставить выделение как есть и удалить данные только в выделенном диапазоне. Важно помнить, что если не расширить диапазон, то данные будут изменены лишь в одном столбце, а данные в прилегающем столбце останутся без малейших изменений.
Появится окно с параметрами удаления дубликатов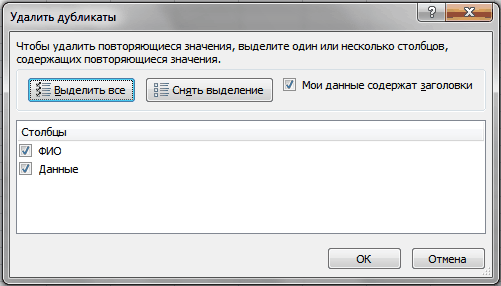
Ставите галочки напротив тех столбцов, дубликаты в которых надо удалить и жмете Ок. Если в выделенном диапазоне так же расположены заголовки данных, то лучше поставить флаг Мои данные содержат заголовки , чтобы случайно не удалить данные в таблице(если они вдруг полностью совпадают со значением в заголовке) .
Способ 1: Расширенный фильтр
В случае с Excel 2003 все посложнее. Там нет такого инструмента, как Удалить дубликаты
. Но зато есть такой замечательный инструмент, как Расширенный фильтр
. В 2003 этот инструмент можно найти в Данные
-Фильтр
-Расширенный фильтр
. Прелесть этого метода в том, с его помощью можно не портить исходные данные, а создать список в другом диапазоне. В 2007-2010 Excel, он тоже есть, но немного запрятан. Расположен на вкладке Данные (Data)
, группа Сортировка и фильтр (Sort & Filter)
- Дополнительно (Advanced)
Как его использовать: запускаем указанный инструмент - появляется диалоговое окно:
- Обработка: Выбираем Скопировать результат в другое место (Copy to another location) .
- Исходный диапазон (List range) : Выбираем диапазон с данными(в нашем случае это А1:А51) .
- Диапазон критериев (Criteria range) : в данном случае оставляем пустым.
- Поместить результат в диапазон (Copy to) : указываем первую ячейку для вывода данных - любую пустую(на картинке - E2) .
- Ставим галочку Только уникальные записи (Unique records only) .
- Жмем Ок .
Примечание: если вы хотите поместить результат на другой лист, то просто так указать другой лист не получится. Вы сможете указать ячейку на другом листе, но...Увы и ах...Excel выдаст сообщение, что не может скопировать данные на другие листы. Но и это можно обойти, причем довольно просто. Надо всего лишь запустить Расширенный фильтр с того листа, на который хотим поместить результат. А в качестве исходных данных выбираем данные с любого листа - это дозволено.
Так же можно не выносить результат в другие ячейки, а отфильтровать данные на месте. Данные от этого никак не пострадают - это будет обычная фильтрация данных.
Для этого надо просто в пункте Обработка выбрать Фильтровать список на месте (Filter the list, in-place) .
Способ 2: Формулы
Этот способ сложнее в понимании для неопытных пользователей, но зато он создает список уникальных значений, не изменяя при этом исходные данные. Ну и он более динамичен: если изменить данные в исходной таблице, то изменится и результат. Иногда это бывает полезно. Попытаюсь объяснить на пальцах что и к чему: допустим, список с данными у Вас расположен в столбце А
(А1:А51
, где А1
- заголовок). Выводить список мы будем в столбец С
, начиная с ячейки С2
. Формула в C2
будет следующая:
{=ИНДЕКС($A$2:$A$51 ;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1 ; $A$2:$A$51)=0;СТРОКА($A$1:$A$50));1))}
{=INDEX($A$2:$A$51 ;SMALL(IF(COUNTIF($C$1:C1 ; $A$2:$A$51)=0;ROW($A$1:$A$50));1))}
Детальный разбор работы данной формулы приведен в статье:
Надо отметить, что эта формула является формулой массива . Об этом могут сказать фигурные скобки, в которые заключена данная формула. А вводится такая формула в ячейку сочетанием клавиш - Ctrl
+Shift
+Enter
. После того, как мы ввели эту формулу в C2
мы её должны скопировать и вставить в несколько строк так, чтобы точно отобразить все уникальные элементы. Как только формула в нижних ячейках вернет #ЧИСЛО!
- это значит все элементы отображены и ниже протягивать формулу нет смысла. Чтобы ошибку избежать и сделать формулу более универсальной(не протягивая каждый раз до появления ошибки) можно использовать нехитрую проверку:
для Excel 2007 и выше:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$51 ;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1 ; $A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));"")}
{=IFERROR(INDEX($A$2:$A$51 ;SMALL(IF(COUNTIF($C$1:C1 ; $A$2:$A$51)=0;ROW($A$1:$A$50));1));"")}
для Excel 2003:
{=ЕСЛИ(ЕОШ(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1 ; $A$2:$A$51)=0;СТРОКА($A$1:$A$50));1));"";ИНДЕКС($A$2:$A$51 ;НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($C$1:C1 ; $A$2:$A$51)=0;СТРОКА($A$1:$A$50));1)))}
{=IF(ISERR(SMALL(IF(COUNTIF($C$1:C1 ; $A$2:$A$51)=0;ROW($A$1:$A$50));1));"";INDEX($A$2:$A$51 ;SMALL(IF(COUNTIF($C$1:C1 ; $A$2:$A$51)=0;ROW($A$1:$A$50));1)))}
Тогда вместо ошибки #ЧИСЛО! (#NUM!)
у вас будут пустые ячейки(не совсем пустые, конечно - с формулами:-))
.
Чуть подробнее про отличия и нюансы формул ЕСЛИОШИБКА и ЕСЛИ(ЕОШ можно прочесть в этой статье: Как в ячейке с формулой вместо ошибки показать 0
Способ 3: код VBA
Данный подход потребует разрешения макросов и базовых знаний о работе с ними. Если не уверены в своих знаниях для начала рекомендую прочитать эти статьи:
- Что такое макрос и где его искать? к статье приложен видеоурок
- Что такое модуль? Какие бывают модули? потребуется, чтобы понять куда вставлять приведенные ниже коды
Оба приведенных ниже кода следует помещать в стандартный модуль . Макросы должны быть разрешены.
Исходные данные оставим в том же порядке - список с данными расположен в столбце "А "(А1:А51 , где А1 - заголовок) . Только выводить список мы будем не в столбец С , а в столбец Е , начиная с ячейки Е2 :
Sub Extract_Unique() Dim vItem, avArr, li As Long ReDim avArr(1 To Rows.Count, 1 To 1) With New Collection On Error Resume Next For Each vItem In Range("A2", Cells(Rows.Count, 1).End(xlUp)).Value "Cells(Rows.Count, 1).End(xlUp) – определяет последнюю заполненную ячейку в столбце А.Add vItem, CStr(vItem) If Err = 0 Then li = li + 1: avArr(li, 1) = vItem Else: Err.Clear End If Next End With If li Then .Resize(li).Value = avArr End Sub
С помощью данного кода можно извлечь уникальные не только из одного столбца, но и из любого диапазона столбцов и строк. Если вместо строки
Range("A2", Cells(Rows.Count, 1).End(xlUp)).Value
указать Selection.Value , то результатом работы кода будет список уникальных элементов из выделенного на активном листе диапазона. Только тогда неплохо бы и ячейку вывода значений изменить - вместо
поставить ту, в которой данных нет.
Так же можно указать конкретный диапазон:
Range("C2", Cells(Rows.Count, 3).End(xlUp)).Value
Универсальный код выбора уникальных значений
Код ниже можно применять для любых диапазонов. Достаточно запустить его, указать диапазон со значениями для отбора только неповторяющихся(допускается выделение более одного столбца) и ячейку для вывода результата. Указанные ячейки будут просмотрены, из них будут отобраны только уникальные значения(пустые ячейки при этом пропускаются) и результирующий список будет записан, начиная с указанной ячейки.
| Sub Extract_Unique() Dim x, avArr, li As Long Dim avVals Dim rVals As Range, rResultCell As Range On Error Resume Next "запрашиваем адрес ячеек для выбора уникальных значений Set rVals = Application.InputBox("Укажите диапазон ячеек для выборки уникальных значений" , "Запрос данных" , "A2:A51" , Type :=8) If rVals Is Nothing Then "если нажата кнопка Отмена Exit Sub End If "если указана только одна ячейка - нет смысла выбирать If rVals.Count = 1 Then MsgBox "Для отбора уникальных значений требуется указать более одной ячейки" , vbInformation, "www.сайт" Exit Sub End If "отсекаем пустые строки и столбцы вне рабочего диапазона Set rVals = Intersect(rVals, rVals.Parent.UsedRange) "если указаны только пустые ячейки вне рабочего диапазона If rVals Is Nothing Then MsgBox "Недостаточно данных для выбора значений" , vbInformation, "www.сайт" Exit Sub End If avVals = rVals.Value "запрашиваем ячейку для вывода результата Set rResultCell = Application.InputBox("Укажите ячейку для вставки отобранных уникальных значений" , "Запрос данных" , "E2" , Type :=8) If rResultCell Is Nothing Then "если нажата кнопка Отмена Exit Sub End If "определяем максимально возможную размерность массива для результата ReDim avArr(1 To Rows.Count, 1 To 1) "при помощи объекта Коллекции(Collection) "отбираем только уникальные записи, "т.к. Коллекции не могут содержать повторяющиеся значения With New Collection On Error Resume Next For Each x In avVals If Len(CStr(x)) Then "пропускаем пустые ячейки .Add x, CStr(x) "если добавляемый элемент уже есть в Коллекции - возникнет ошибка "если же ошибки нет - такое значение еще не внесено, "добавляем в результирующий массив If Err = 0 Then li = li + 1 avArr(li, 1) = x Else "обязательно очищаем объект Ошибки Err.Clear End If End If Next End With "записываем результат на лист, начиная с указанной ячейки If li Then rResultCell.Cells(1, 1).Resize(li).Value = avArr End Sub |
Sub Extract_Unique() Dim x, avArr, li As Long Dim avVals Dim rVals As Range, rResultCell As Range On Error Resume Next "запрашиваем адрес ячеек для выбора уникальных значений Set rVals = Application.InputBox("Укажите диапазон ячеек для выборки уникальных значений", "Запрос данных", "A2:A51", Type:=8) If rVals Is Nothing Then "если нажата кнопка Отмена Exit Sub End If "если указана только одна ячейка - нет смысла выбирать If rVals.Count = 1 Then MsgBox "Для отбора уникальных значений требуется указать более одной ячейки", vbInformation, "www.сайт" Exit Sub End If "отсекаем пустые строки и столбцы вне рабочего диапазона Set rVals = Intersect(rVals, rVals.Parent.UsedRange) "если указаны только пустые ячейки вне рабочего диапазона If rVals Is Nothing Then MsgBox "Недостаточно данных для выбора значений", vbInformation, "www..Value "запрашиваем ячейку для вывода результата Set rResultCell = Application.InputBox("Укажите ячейку для вставки отобранных уникальных значений", "Запрос данных", "E2", Type:=8) If rResultCell Is Nothing Then "если нажата кнопка Отмена Exit Sub End If "определяем максимально возможную размерность массива для результата ReDim avArr(1 To Rows.Count, 1 To 1) "при помощи объекта Коллекции(Collection) "отбираем только уникальные записи, "т.к. Коллекции не могут содержать повторяющиеся значения With New Collection On Error Resume Next For Each x In avVals If Len(CStr(x)) Then "пропускаем пустые ячейки.Add x, CStr(x) "если добавляемый элемент уже есть в Коллекции - возникнет ошибка "если же ошибки нет - такое значение еще не внесено, "добавляем в результирующий массив If Err = 0 Then li = li + 1 avArr(li, 1) = x Else "обязательно очищаем объект Ошибки Err.Clear End If End If Next End With "записываем результат на лист, начиная с указанной ячейки If li Then rResultCell.Cells(1, 1).Resize(li).Value = avArr End Sub
Способ 4: Сводные таблицы
Несколько нестандартный способ извлечения уникальных значений.
- Выделяем один или несколько столбцов в таблице, переходим на вкладку Вставка (Insert) -группа Таблица (Table) -Сводная таблица (PivotTable)
- В диалоговом окне Создание сводной таблицы (Create PivotTable) проверяем правильность выделения диапазона данных (или установить новый источник данных)
- указываем место размещения Сводной таблицы:
- На новый лист (New Worksheet)
- На существующий лист (Existing Worksheet)
- подтверждаем создание нажатием кнопки OK
Т.к. сводные таблицы при обработке данных, которые помещаются в область строк или столбцов, отбирают из них только уникальные значения для последующего анализа, то от нас ровным счетом ничего не требуется, кроме как создать сводную таблицу и поместить в область строк или столбцов данные нужного столбца.
На примере приложенного к статье файла я:

В чем неудобство работы со сводными в данном случае: при изменении в исходных данных сводную таблицу придется обновлять вручную: Выделить любую ячейку сводной таблицы -Правая кнопка мыши -Обновить (Refresh) или вкладка Данные (Data) -Обновить все (Refresh all) -Обновить (Refresh) . А если исходные данные пополняются динамически и того хуже - надо будет заново указывать диапазон исходных данных. И еще один минус - данные внутри сводной таблицы нельзя менять. Поэтому если с полученным списком необходимо будет работать в дальнейшем, то после создания нужного списка при помощи сводной его надо скопировать и вставить на нужный лист.
Чтобы лучше понимать все действия и научиться обращаться со сводными таблицами настоятельно рекомендую ознакомиться со статьей Общие сведения о сводных таблицах - к ней приложен видеоурок, в котором я наглядно демонстрирую простоту и удобство работы с основными возможностями сводных таблиц.
В приложенном примере помимо описанных приемов, записана чуть более сложная вариация извлечения уникальных элементов формулой и кодом, а именно: извлечение уникальных элементов по критерию . О чем речь: если в одном столбце фамилии, а во втором(В) некие данные(в файле это месяцы) и требуется извлечь уникальные значения столбца В только для выбранной фамилии. Примеры подобных извлечений уникальных расположены на листе Извлечение по критерию .
Скачать пример:
(108,0 KiB, 14 501 скачиваний)
Статья помогла? Поделись ссылкой с друзьями! ВидеоурокиВоспользуемся возможностями условного форматирования. Эту тему мы уже рассматривали в статье , а теперь применим для решения другой задачи.
Ищем повторяющиеся записи в Excel 2007
Выделим столбец, в котором будем искать дубликаты (в нашем примере это столбец с каталожными номерами), и на главной вкладке ищем кнопку «Условное форматирование». Далее по пунктам, как на рисунке.
В новом окне нам остается только согласиться с предлагаемым цветовым решением (или выбрать другое) и нажать «ОК».
Теперь повторяющиеся значения у нас окрашены в красный цвет. Но они разбросаны по всей таблице и это неудобно. Нужно отсортировать строки, чтобы собрать их в кучку. Обратите внимание, что в приведенной таблице есть столбец «№ п/п», содержащий номера строк. Если у вас его нет, его следует сделать, чтобы мы потом смогли восстановить исходный порядок данных в таблице.
Выделяем всю таблицу, переходим на вкладку «Данные» и жмем на кнопку «Сортировка». В новом окне нам нужно задать порядок сортировки. Выставляем нужные нам значения и добавляем следующий уровень. Нам нужно отсортировать строки сначала по цвету ячеек, а потом по значению в ячейке, чтобы дубликаты оказались рядом друг с другом.
Разбираемся с найденными дубликатами. В данном случае повторяющиеся строки можно просто удалить.
Обратите внимание, что по мере удаления дубликатов красные ячейки возвращают себе белый цвет.
Избавившись от цветных ячеек, снова выделим всю таблицу и отсортируем ее по столбцу «№п/п». После этого останется только поправить сбившуюся из-за удаленных строк нумерацию.
Как это сделать в Excel 2003
Здесь будет немного сложнее – придется использовать логическую функцию «СЧЕТЕСЛИ()».
Войдите в ячейку с первым значением, среди которых вы будете искать дубликаты.
- Формат.
- Условное форматирование.
В первом поле выберите «Формула» и введите формулу «=СЧЕТЕСЛИ(C;RC)>1». Только не забудьте вовремя переключить раскладку – «СЧЕТЕСЛИ» набирается в русской раскладке, а «(C;RC)>1» в английской.
Цвет выберите, нажав на кнопку «Формат» на закладке «Вид».
Теперь нам нужно скопировать этот формат на весь столбец.
- Правка.
- Копировать.
Выделяем весь столбец с проверяемыми данными.
- Правка.
- Специальная вставка.

Выбираем «Форматы», «ОК» и условное форматирование скопировалось на весь столбец.
Покоряйте Excel и до новых встреч!
В сегодняшних Excel файлах дубликаты встречаются повсеместно. К примеру, когда вы создаете составную таблицу из других таблиц, вы можете обнаружить в ней повторяющиеся значения, или в файле с общим доступом внесли одинаковые данные два разных пользователя, что привело к задвоению и т.д. Дубликаты могут возникнуть в одном столбце, в нескольких столбцах или даже во всем листе. В Microsoft Excel реализовано несколько инструментов поиска, выделения и, при необходимости, удаления повторяющихся значений. Ниже описаны основные методики определения дубликатов в Excel.
1. Удаление повторяющихся значений в Excel (2007+)
Предположим, у вас имеется таблица, состоящая из трех столбцов, в которой присутствуют одинаковые записи и вам необходимо избавится от них. Выделяем область таблицы, в которой хотите удалить повторяющиеся значения. Вы можете выделить один или несколько столбцов, или всю таблицу целиком. Переходим по вкладке Данные в группу Работа с данными, щелкаем по кнопке Удалить дубликаты.
Если в каждом столбце таблицы имеется заголовок, установить маркер Мои данные содержат заголовки. Также проставляем маркеры напротив тех столбцов, в которых требуется произвести поиск дубликатов.

Щелкаем ОК, диалоговое окно будет закрыто и строки, содержащие дубликаты будут удалены.
Данная функция предназначена для удаления записей, которые полностью дублируют строки в таблице. Если вы выделили не все столбцы для определения дубликатов, строки с повторяющимися значениями также будут удалены.
2. Использование расширенного фильтра для удаления дубликатов
Выберите любую ячейку в таблице, перейдите по вкладке Данные в группу Сортировка и фильтр, щелкните по кнопке Дополнительно.

В появившемся диалоговом окне Расширенный фильтр, необходимо установить переключатель в положение скопировать результат в другое место, в поле Исходный диапазон указать диапазон, в котором находится таблица, в поле Поместить результат в диапазон указать верхнюю левую ячейку будущей отфильтрованной таблицы и установить маркер Только уникальные значения. Щелкаем ОК.

На месте, указанном для размещения результатов работы расширенного фильтра, будет создана еще одна таблица, но уже с отфильтрованными, по уникальным значениям, данными.

3. Выделение повторяющихся значений с помощью условного форматирования в Excel (2007+)
Выделяем таблицу, в которой необходимо обнаружить повторяющиеся значения. Переходим по вкладкеГлавная в группу Стили, выбираем Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения.

В появившемся диалоговом окне Повторяющиеся значения, необходимо выбрать формат выделения дубликатов. У меня по умолчанию установлено светло-красная заливка и темно-красный цвет текста. Обратите внимание, в данном случае Excel будет сравнивать на уникальность не всю строку таблицы, а лишь ячейку столбца, поэтому если у вас имеются повторяющиеся значения только в одном столбце, Excel отформатирует их тоже. На примере вы можете увидеть, как Excel залил некоторые ячейки третьего столбца с именами, хотя вся строка данной ячейки таблицы уникальна.

4. Использование сводных таблиц для определения повторяющихся значений
Воспользуемся уже знакомой нам таблицей с тремя столбцами и добавим четвертый, под названиемСчетчик, и заполним его единицами (1). Выделяем всю таблицу и переходим по вкладке Вставка в группу Таблицы, щелкаем по кнопке Сводная таблица.

Создаем сводную таблицу. В поле Название строк помещаем три первых столбца, в поле Значенияпомещаем столбец со счетчиком. В созданной сводной таблице, записи со значением больше единицы будут дубликатами, само значение будет означать количество повторяющихся значений. Для большей наглядности, можно отсортировать таблицу по столбцу Счетчик, чтобы сгруппировать дубликаты.

Здравствуйте дорогие читатели. Сегодня мы с вами поговорим о дубликатах файлов, а также о методах борьбы с ними.
Исходя из самого названия вы, наверное, уже догадались, что это за файлы. Такие вот повторяющиеся файлы очень загрязняют жесткий диск, поэтому от них нужно периодически избавляться.
Дубликаты появляются на компьютере произвольно и из-за невнимательности пользователей. Хотя все мы люди и нам свойственно накапливать всякую всячину. Какой бы большой объем памяти не имел ваш жесткий диск – после удалению дубликатов он станет намного свободнее, нежели был до совершения этого процесса.
К большому сожалению, удаление дубликатов файлов невозможно произвести без посторонних программ. Разработчики Windows почему-то упустили этот момент, но люди нашли выход. В интернете есть масса бесплатных программ для избавления от дублирующих файлов. Ниже я приведу три лучшие из них, а также дам вам возможность их скачать.
CloneSpy
Очень простая и удобная утилита для очистки вашего компьютера от дубликатов файлов. После запуска CloneSpy производит поиск по контрольным суммам файлов, игнорируя при этом дату и время их создания, размер и т.д. Такой метод поиска дубликатов файлов позволяет сделать более точный и детальный поиск.
Но CloneSpy имеет также и минус, поскольку в результатах поиска, помимо копий может отобразить файлы с одинаковым именем.
Скачать бесплатно утилиту CloneSpy
Auslogics Duplicate File Finder
Более мощная программа поиска файлов-дублей. Делает детальный анализ жесткого диска на наличие одинаковых файлов, в конце которого вы получите список со всеми найденными дубликатами.
Я заметил, что Auslogics Duplicate File Finder хорошо специализируется на поиске мультимедийных файлов-дублей, а это гигабайты одинаковых музыкальных треков, фильмов, картинок и т.д.
Скачать бесплатно программу Auslogics Duplicate File Finder
DupKiller
Тоже очень хорошая программа для поиска и удаления дубликатов файлов. Очень понравилась функция установки процента допустимого совпадения, который вы можете установить вручную перед запуском анализа жесткого диска.Если Вы работаете с большими количеством информации в Excel и регулярно добавляете ее, например, данные про учеников школы или сотрудников компании, то в таких таблицах могут появиться повторяющиеся значения, другими словами – дубликаты.
В данной статье мы рассмотрим, как найти, выделить, удалить и посчитать количество повторяющихся значений в Эксель.
Как найти и выделить
Найти и выделить дубликаты в документе можно, используя условное форматирование в Эксель . Выделите весь диапазон данных в нужной таблице. На вкладке «Главная» кликните на кнопочку «Условное форматирование» , выберите из меню «Правила выделения ячеек» – «Повторяющиеся значения» .
В следующем окне выберите из выпадающего списка «повторяющиеся» , и цвет для ячейки и текста, в который нужно закрасить найденные дубликаты. Затем нажмите «ОК» и программа выполнит поиск дубликатов.

В примере Excel выделил розовым всю одинаковую информацию. Как видите, данные сравниваются не построчно, а выделяются одинаковые ячейки в столбцах. Поэтому выделена ячейка «Саша В.» . Таких учеников может быть несколько, но с разными фамилиями.

Как посчитать
Если Вам нужно найти и посчитать количество повторяющихся значений в Excel, создадим для этого сводную таблицу Excel. Добавляем в исходную столбец «Код» и заполняем его «1» : ставим 1, 1 в первых двух ячейка, выделяем их и протягиваем вниз. Когда будут найдены дубликаты для строк, каждый раз значение в столбце «Код» будет увеличиваться на единицу.
Выделяем все вместе с заголовками, переходим на вкладку «Вставка» и нажимаем кнопочку «Сводная таблица» .
Чтобы более подробно узнать, как работать со сводными таблицами в Эксель , прочтите статью перейдя по ссылке.

В следующем окне уже указаны ячейки диапазона, маркером отмечаем «На новый лист» и нажимаем «ОК» .

Справой стороны перетаскиваем первые три заголовка в область «Названия строк» , а поле «Код» перетаскиваем в область «Значения» .

В результате получим сводную таблицу без дубликатов, а в поле «Код» будут стоять числа, соответствующие повторяющимся значениям в исходной таблице – сколько раз в ней повторялась данная строка.
Для удобства, выделим все значения в столбце «Сумма по полю Код» , и отсортируем их в порядке убывания.

Думаю теперь, Вы сможете найти, выделить, удалить и даже посчитать количество дубликатов в Excel для всех строк таблицы или только для выделенных столбцов.
Оценить статью:







